AA sort
Aligned-Access sort (AA-sort) 访问对齐排序,可支持SIMD和多线程的排序算法。
AA-sort: A new parallel sorting algorithm for multi-core SIMD processors
算法主要流程分三步:
- (1) Divide all of the data into blocks that fit into the cache of the processor.
- (2) Sort each block with the in-core sorting algorithm.
- (3) Merge the sorted blocks with the out-of-core algorithm. First we present these two sorting algorithms and then illustrate the overall sorting scheme.
1. Divide data:
切分数据的依据是Cache能存下的数据量为一个batch,在文章中,作者使用了L2Cache/2作为参考值。
2. In-core algorithm:Vectorized Combsort
Combsort梳子排序是冒泡排序的优化版,由gap=n/k开始依次比较交换a[i], a[i+gap],然后gap=gap/k重复,直到gap=1,一直冒泡直到排好序;一般取k=1.24或者1.3。
combsort中,当gap较大时,是符合SIMD优化原则的,但是当gap<4时,就需要寄存器内不同通道的数据相互比较了。
对此,作者提出将原数据reshape(-1,4)后进行排序的方法:
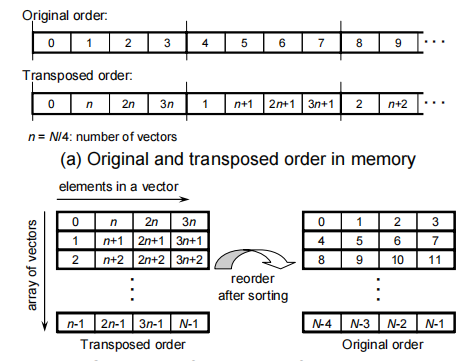
如上图,假设上方original order是希望得到的排序好的数据,下面Transposed order是reshape(-1,4)后的数据,将数据显示成矩阵形式则成为左下角的样子,观察这个矩阵,对于每一列,都是排序好的,而每一列的数都比下一列的数要小。
而在SIMD架构中,得到左下角这个矩阵则比要直接得到original order要简单,因为最直接的大小关系从左右相邻的数比较,变成了上下寄存器之间比较,而这是SIMD所支持的。因此只要从原始数据得到左下角的矩阵,就能通过重排得到排序好的数据。
in-core排序过程:
对每组4个数据排序,确保v0<v1<v2<v3
以寄存器为单位的梳子排序:主要流程即梳子排序的过程,数与数的比较替换成寄存器的比较vector_cmpswap;除此之外还需要增加一些操作以确保每一列的数都比后一列的数要小的关系;方法是在对一个gap完成一次排序后,依次对后gap组数据和前gap组数据执行操作vector_cmpswap_skew;最终达到排序完成状态。伪代码如下图所示:
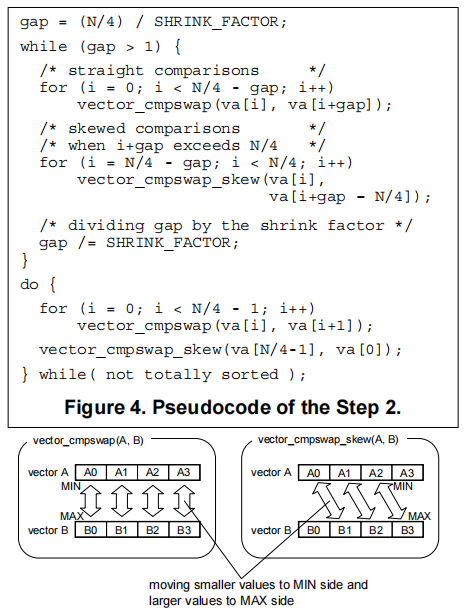
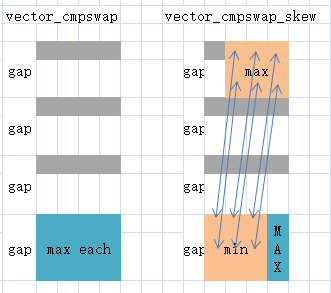
vector_cmpswap:直接比较交换两个寄存器对应通道的值。
vector_cmpswap_skew:比较交换两个寄存器错位通道的值,大小关系与vector_cmpswap相反。
重排数据,排序完成。
3. out-of-core algorithm:Merge
in-core algorithm后,得到了M组排好序的数据;out-of-core algorithm做的是将他们合并;
合并流程类似于普通数组合并,两个头指针分别指向两个数组,数据较大的指针pop数据后移,直到两个数组完全合并;只不过在这里,单位是寄存器。
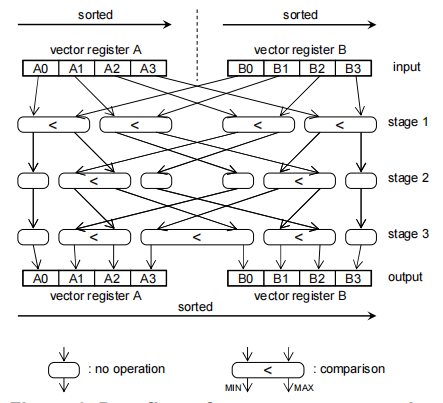
合并算法过程(以递减排序为例):从两组数据中读取数据到两个寄存器,两寄存器合并重排得到较小一半数据和较大的一半数据,比较合并的过程如下图所示,较大的数据用作输出,较小的数据放寄存器等待下一次比较;然后输出数据的寄存器从两组剩余数据中选择一组读取新的待合并数据,选择的依据是首位数据较大的;然后不断重复以上过程。
mark: