SIMD优化
向量化计算
向量化计算是一种特殊的并行计算的方式,相比于一般程序在同一时间只执行一个操作的方式,它可以在同一时间执行多次操作,通常是对不同的数据执行同样的一个或一批指令,或者说把指令应用于一个数组/向量。
SIMD
Single instruction, multiple data 单指令多数据流
依赖于CPU的向量寄存器,一次指令对多个数据进行相同的操作。
- 数据内存中连续储存
- 对于连续数据的操作相同或者规律相同
- 处理的数据间没有相互依赖关系
- 寄存器带宽比数据类型大。。数据对齐
SIMD代码改造优化的tips:
循环优化
1 | // 连续内存数据循环在最内层 |
移除分支
关于分支预测失败的性能损耗可以参考这里(尽管分支预测成功率很高)
等效的数学公式替代分支
1 | for (int c = 0; c < arraySize; c++) |
数据重排
必要的时候对数据进行重新排列,以配合SIMD达到性能提升。
输出blob的reshape、对齐
因为SIMD的特性,除了需要保证数据对齐128字节,而且要求数据内存连续;所以需要根据具体的算法流程确定好数据的内存排布,如网络输出应该是NCHW还是NHWC还是要NC4HW4对齐,在实现前需要确定清楚。
数据处理前对读取的数据在寄存器内部重排
有时候在需要处理相邻的数据时,使用SIMD可能达不到好的效果,这时候可以考虑将数据进行转置,比如AA-sort中进行in-core排序前对4x4的数据进行了转置,以便于后续的比较,见这里;其实就是reshape的衍生。
消除数据存取延迟与数据依赖延迟
由于CPU指令流水线等机制,消除指令间的依赖关系能够提高指令的执行效率
通过数据预取减少内存读写延迟
数据预取能加快数据读取速度
通过指令横向扩展抵消内存读写延迟
ld v1 → dosth v1 → st v1 指令可能因为内存读写阻塞
横向扩展 ld v1, v2 → dosth v1 ,v2→ st v1 ,v2 像这样一次处理两组,则内存阻塞等待时间相当于减少一半
通过指令横向扩展消除数据依赖延迟
v2 = dosth v1 → v3 = dosth v2
横向扩展 v2, v22 = dosth v1, v11→ v3, v33 = dosth v2, v22
可以消除指令间的依赖关系,提高执行效率
NEON
ARM cpu拓展结构,包括64-bit和32个128-bit的寄存器,以提供SIMD方式高效的图片视频数据处理能力。提供汇编代码和内联函数调用的使用方式。
寄存器结构:Elements are the standard Neon-supported widths of 8 (B), 16 (H), 32 (S), or 64 (D) bits.
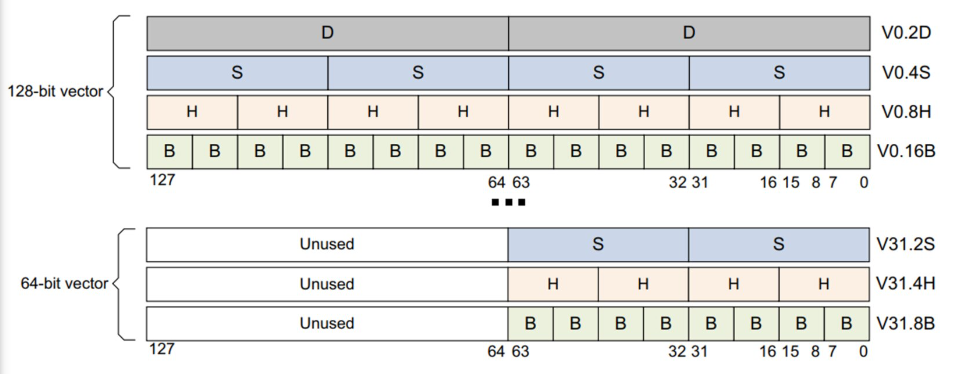
数据存取,除了提供数据顺序存取,还提供数据交叉存取,方便处理多通道的数据。


其中内联函数仅提供从低位0开始填充寄存器的读取方式,而汇编可以指定寄存器偏移。如使用方式为:LD3 { V0.B, V1.B, V2.B }[4] , [x0], #48

其他资料
官方文档整理了NEON数据重排可以用到的一些指令:https://developer.arm.com/architectures/instruction-sets/simd-isas/neon/neon-programmers-guide-for-armv8-a/coding-for-neon/permutation-neon-instructions
其他的内联函数指令查询:https://developer.arm.com/architectures/instruction-sets/simd-isas/neon/intrinsics?search=vtrn
网友提供的内联指令中文介绍: https://github.com/rogerou/Arm-neon-intrinsics](https://github.com/rogerou/Arm-neon-intrinsics
开发指南: https://developer.arm.com/documentation/den0018/a (离线版本:DEN0018A_neon_programmers_guide.pdf
ARM、neon汇编指令中文介绍:RealView汇编指南中文版.pdf